Understanding Deformable Alignment in
Video Super-Resolution
3 CUHK – SenseTime Joint Lab, The Chinese University of Hong Kong
4 Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences

Comparison to Flow-Based Alignment. We analyze the learnable offsets in deformable convolution (DCN) and show that the offsets are highly related to optical flow. By learning multiple offsets, deformable alignment allows information to be aggregated from multiple locations, leading to better-aligned features, and hence high-quality outputs.
Highlights
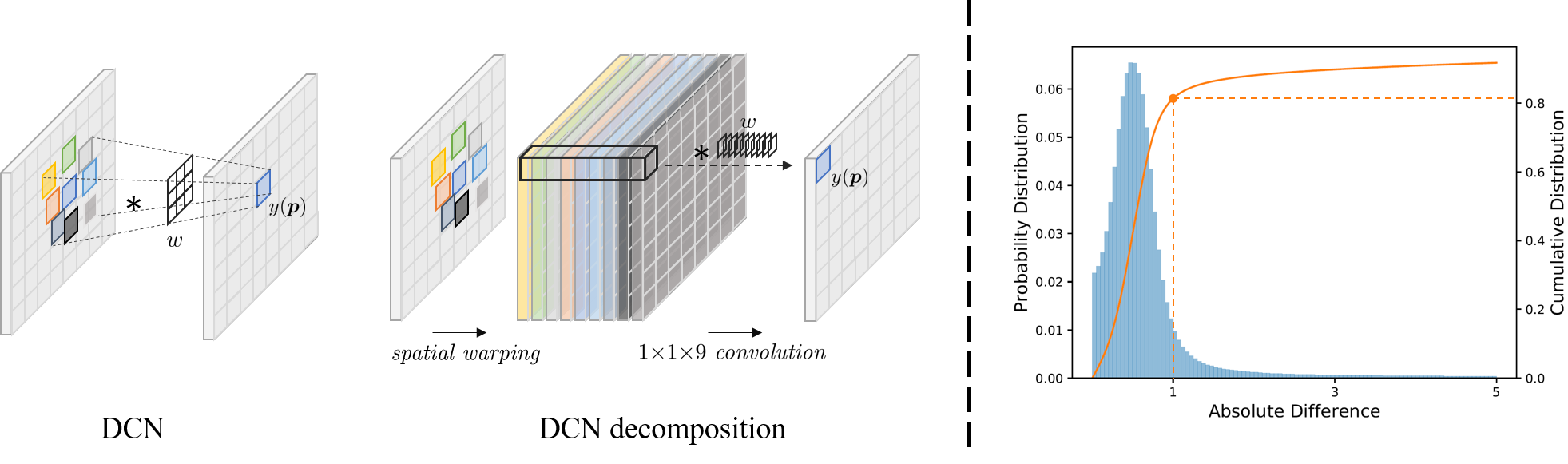
- Deformable convolution (DCN) can be decomposed into a combination of spatial warpings and convolutions.
- The DCN offsets are highly similar to optical flow.
- The superiror performance of deformable alignment over flow-based alignment comes from the offset diversity.
- We propose an offset-fidelity loss to stabilize the training of deformable alignment.

Abstract
Deformable convolution, originally proposed for the adaptation to geometric variations of objects, has recently shown compelling performance in aligning multiple frames and is increasingly adopted for video super-resolution. Despite its remarkable performance, its underlying mechanism for alignment remains unclear. In this study, we carefully investigate the relation between deformable alignment and the classic flow-based alignment. We show that deformable convolution can be decomposed into a combination of spatial warping and convolution. This decomposition reveals the commonality of deformable alignment and flow-based alignment in formulation, but with a key difference in their offset diversity. We further demonstrate through experiments that the increased diversity in deformable alignment yields better-aligned features, and hence significantly improves the quality of video super-resolution output. Based on our observations, we propose an offset-fidelity loss that guides the offset learning with optical flow. Experiments show that our loss successfully avoids the overflow of offsets and alleviates the instability problem of deformable alignment. Aside from the contributions to deformable alignment, our formulation inspires a more flexible approach to introduce offset diversity to flowbased alignment, improving its performance.
Analysis
Left: The decomposition of DCN into spatial warpings and convolutions. Right: When setting the number of offsets to 1, over 80% of the offsets have difference to optical flow smaller than 1, demonstrating the high relation between the offsets and optical flow. See our paper for more details.
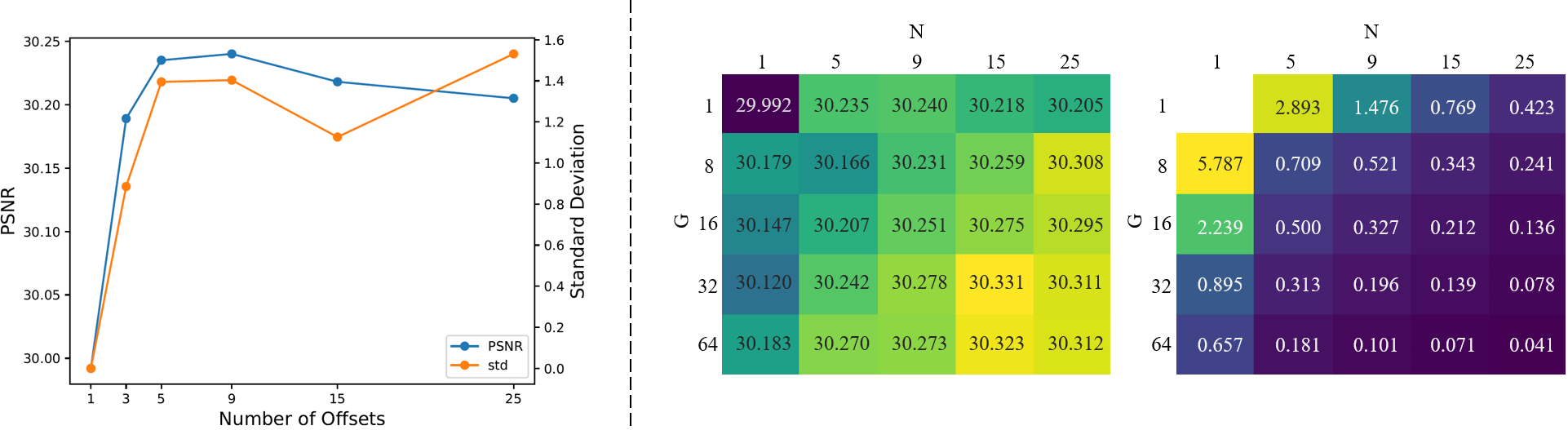
Left: Both the performance and the diversity of the offsets increase with the number of offsets. Right: The performance tends to saturate when number of offsets increases (marginal increase become small).
Offset-Fidelity Loss
Left: The formulation and quantitative comparison. The function H denotes the Heaviside step function. Right: By using our offset-fidelity loss to push the learnable offsets towards optical flow (while preserving offset diversity), the offset overflow problem is alleviated, leading to better outputs.

Citation
@InProceedings{chan2021understanding,
author = {Chan, Kelvin CK and Wang, Xintao and Yu, Ke and Dong, Chao and Loy, Chen Change},
title = {Understanding Deformable Alignment in Video Super-Resolution},
booktitle = {AAAI Conference on Artificial Intelligence},
year = {2021}
}
Contact
If you have any question, please contact Kelvin Chan at chan0899@e.ntu.edu.sg.